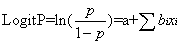多重应答(Multiple Response),又称多选题,是市场调查研究中十分常见的数据形式。多重应答数据本质上属于分类数据,但由于各选项均是对同一个问题的回答,之间存在一定的相关,将各选项单独进行分析并不恰当。对多重应答数据最常见的分析是使用SPSS中的“Multiple Response”命令,通过定义变量集的方式,对选项进行简单的频数分析和交叉分析。笔者认为,该分析方法对调查数据的开发利用往往是不够的,我们还可以使用其他分析方法对数据信息进行深度挖掘。
一、两种数据录入方式
比如说在某次民意调查中,我们希望了解公众评价宜居城市时,到底是城市的哪一些特征决定人们对该城市宜居性的评估。为此,我们在研究中设计了14项标准请被访者从中选出他们在进行宜居评价时最看重的5项标准(关于宜居标准的具体探讨,参见本刊2006年第8期)。
选项包括:
这是一道典型的多重应答题。统计软件中对多重应答的标准纪录方式有两种:(1)多重二分法(Multiple dichotomy method)。对于多项选择题的每一个选项看作一个变量来定义。0代表没有被选中,1代表被选中。这样,多项选择题中有几个选项,就会变成有几个单选变量。这些单选变量的选项都只有两个,即0或1。比如在上述例子中,我们就可以设置14个单选变量,来标示某选项是否被选中;(2)多重分类法(Multiple category method)。多项选择题中有几个选项,就定义几个单选变量。每个变量的选项都一样,都和多项选择题的选项相同。每个变量代表被调查者的一次选择,即纪录的是被选中的选项的代码。如上述例子中,我们可以设置X1~X5共5个变量,每个变量的选项兼为从1到14的14项宜居标准。很多情况下,当问卷中不限定被访者可选择的选项数量时,被调查者可能不会全部选项都选,因此在数据录入时,一般从这些变量的最前面几个变量开始录入,这样最后面几个变量自然就是缺失值。当被调查者对多项选择题中的选项全部选择时,这些变量中都有一个选项代码,此时没有缺失值。
事实上,假如被访者所选择的各项选之间不涉及顺序问题(如上述例子中,不需要受访者给出哪种因素最重要,哪种次重要),那么这两种输入方法所表达的数据信息是一样的。但在实际操作中,如果选择项较多,而被调查者最多只选择其中少数几项时,采用多重二分法录入就显得繁琐,输入数据时容易出错。尤其是当样本量增大时,采用多重二分法录入就大大增加了录入的工作量,不利于提高工作效率。为此,一般的市场调查公司大都采用多重分类法的录入方式。
二、两种数据录入格式的转换
实际上,只有多重二分法的录入方式才是符合统计分析原则的数据排列格式,能够直接进行后续的统计推断。多重分类法只是一种简化纪录方式,需要转化为前者后方可进行统计推断。
采用多重分类法录入的数据如果要转化成虚拟变量(选项为0或1)的形式,以上述公众宜居标准的选择为例,可以采用如下操作命令:
COUNT
New_x1=X1 X2 X3 X4 X5 (1).
EXECUTE.
其中New_x1代表受访者是否选择“社会安全”该选项。显然,如果在X1~X5中受访者选择了“1”(社会安全)选项,那么New_x1的取值为1,如果在X1~X5中受访者没有选择“1”,那么New_x1的取值为0。以同样的思路,我们就可以设置变量New_x2~New_x14了。这样,通过上述数据转换,我们就把X1~X5共5个变量转化成了New_x1~New_x14共14个虚拟变量了。
三、多重应答数据交叉分析
(一)多重应答卡方检验
在SPSS操作中,多重应答变量通过定义变量集之后就可以直接与其他变量进行交叉分析了。这种操作方法使用方便,但是其缺陷是在SPSS操作界面上无法直接实现卡方检验。为此,本文介绍一种进行卡方检验的间接方法。
解决方法与操作:
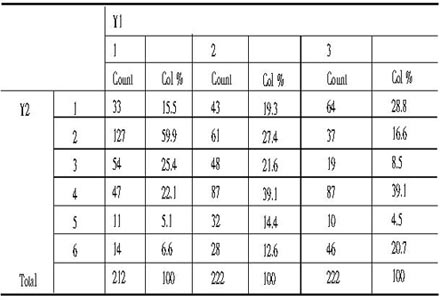
第一步:根据需要做出一个有多重应答问题的交叉表,如表1
表 1 多重应答交叉表
第二步:构成一个与第一步中结构相同的频数全部为“1”的交叉表。可以通过如下操作实现。
在SPSS中,新增加两个变量。
变量I的构成方式:从1到6,重复3次;
变量II的构成方式:1重复6次,2重复6次,3重复6次。
第三步:按照第一步产生的交叉表内的频数,构造变量III。以变量III为权重,对应交叉表中每个组成元素的位置进行加权。
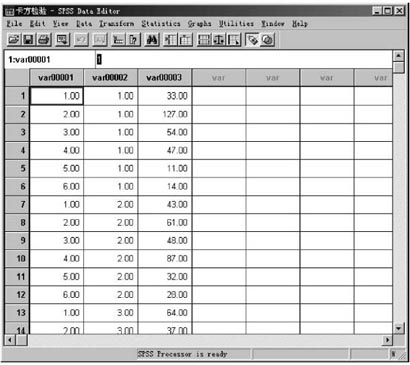
最后的结果如下图:
图 1 生成三个变量
第四步:最后就可以利用加权后的数据,直接选择SPSS中的“Descriptive Statistics”中的“Crosstabs”命令直接进行交叉分析和卡方检验了。
(二)多重应答数据多元交叉比较法
使用上述检验方法操作相对比较复杂,且不能比较具体的每一个选项与其他变量的检验情况。为此,我们也可以将转化后的每一个“虚拟变量”与其他变量(如性别)直接进行卡方检验。
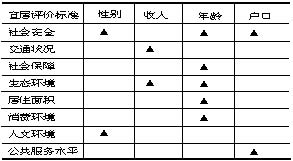
比如在上述“宜居标准”这个例子中,我们把代表不同宜居标准的New_x1~New_x14共14个虚拟变量与“性别”、“户口”、“收入”和“年龄”进行交叉列联分析和卡方显著性检验,为了使检验结果具有可比较性,我们把这4个背景变量都设置为只有两项取值(如收入分为低收入和高收入,年龄分为18~35岁和35岁以上,户口情况分为本地户口和外地户口),这样做出的交叉分析就具有共同的自由度(df=1),可以对各自的卡方值的大小进行比较。检验结果显示,城市不同性别、不同收入、不同户口的市民存在显著差异的宜居因素兼为2个;但是城市不同年龄段人群认为的宜居因素却有5个存在显著性差异。由此可见,不同年龄段的人群在对宜居的标准判断上存在更大的多元化倾向。在建设宜居城市时,为了尽量满足各类群体的需求,可以从先满足不同年龄段市民的宜居需求着手。
表 2 不同类别群体的宜居因素差异比较
注:▲表示该宜居因素在对应的类别群体中存在显著性差异P<0.05
因子分析是利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。因子分析的思想始于1904年查尔斯•斯皮尔曼(Charles Spearman)对学生成绩的研究,近年来,随着电子计算机的发展,人们将因子分析的理论成功地应用于市场研究领域。
例如,某年我们对982名跨国企业经理人和普通员工进行了一项调查,其中有一题我们让受访者选出他们认为的中资跨国企业与外资跨国企业相比,在发展中最急需解决的三项问题是什么,并按重要性排序。
1.资金2.人才3.新制度4.信息5.相关政策6.知识与技术
请排序:第一重要问题_____;第二重要问题_____;第三重要问题_____。
面对上述问题,简单的频数分析显然不能综合地反映问题。而因子分析法不仅可以进行综合分析,发现公因子,而且还可以得到更多的信息。
对上述的选项按三级李克特量表进行处理:凡是选为第一重要因素的赋予10分,选为第二重要因素的赋予7分,选为第三重要因素的赋予4分,没有被选中的因素都设为0分,新设置6个变量(问题的选项有6项),将每个人的回答情况由原来3个变量转换为资金、人才、新制度、信息、相关政策、知识与技术6个变量。具体转换方法如表3。
表 3 变量的转换
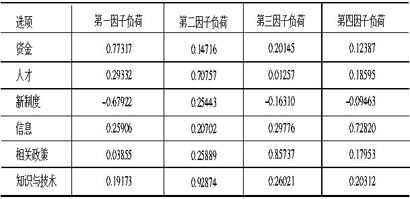
然后对新生成的6个变量进行因子分析,分析结果显示,前4个因子的方差贡献率达到了87.6%。具体结果显示如下:
表 4 旋转后各选项在所提取公因子中的负荷系数
从表中可以看出第一个公因子是资金与新制度;第二个公因子是人才和知识与技术;第三个公因子是相关政策;第四个公因子是信息。这说明中国的跨国企业在发展中最急需解决的问题是资金与新制度,其次是人才和知识与技术,再次是相关政策、信息。该分析结果与频数分析基本一致。并且从因子分析中我们还可得到更多的相关信息。如第一公因子为资金与新制度,但是两个变量的因子载荷符合是相反的,这说明越是关心“资金”的人,越不重视制度创新;其次,信息这一选项被排在最后,从一个侧面说明中资跨国企业与外资跨国企业相比还处于粗放发展阶段,更需要资金、人才和技术支持,信息的功能尚未有效发挥。
五、多重应答数据Logistic回归分析
为了了解不同人群的应答特征,可以将多重应答情况作为因变量,相应的人群特征变量作为影响因素。由于所有选项均为选中或不选中两种取值,因此所有的因变量均为二分类,即建立多元Logistic模型。
Logistic回归方程的基本形式为:
其中,p为事件发生率,xi为影响因素,bi为影响系数,a为常数项。
下面我们以一个具体的例子来说明。
问题【针对企业家提问】:下面我将读出一些对企业家的形象描述,请告诉我其中哪些是您个人期望塑造的企业家形象?【可多选】
选项:
因篇幅所限,这里仅对“关心公益事业的”这一选项的影响因素加以分解。
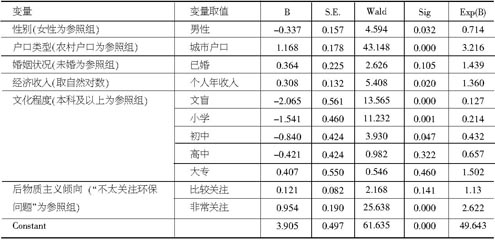
在该Logistic模型中,因变量为在多项选择中是否选择了“关心公益事业”这一选项,选了的赋值为1,没有选的赋值为0。
自变量中的离散变量经过虚拟变量处理。性别以女性为参照类,户口类型以农村户口为参照类,婚姻状况以未婚为参照类,文化程度以本科及以上为参照类。另外,从分布来看,个人年收入严重偏态分布,故取自然对数,使之整体服从正态分布。
自变量中,我们还设计了“后物质主义倾向”这一变量。物质主义和后物质主义是关于价值观的一对概念,传统的强调经济增长和物质安全的价值观为物质主义,而新流行的强调自由、精神生活和生活质量的价值观为后物质主义。我们以“您是否关注当前的环境保护问题”来测量企业家的后物质主义倾向。因为环保问题是目前的热门话题,与企业家的利他主义、社会责任等后现代意识密切相关。该变量以“不太关注”为参照组。
表 5 Logistic 回归结果:是否选择“关心公益事业的”
Logistic回归统计结果表明,假设模型整体检验十分显著(卡方值为239.016,p=0.0001)。除婚姻状况、后物质主义中的“比较关注”以及部分受教育程度对因变量的影响不显著外,其他因素均显著。总的来说,女性企业家比男性企业家更喜欢呈现出“关注公益事业”的形象;城市企业家比农村企业家更倾向于呈现出“关注公益事业”的形象;收入越高、学历越高、后物质主义倾向越强的企业家更希望呈现“关注公益事业”的形象。
长期以来,多重应答资料因其特殊性而无法应用传统的多元统计分析方法加以分析,本文利用数据转换等方式大大丰富了数据建模方法。随着统计方法的不断发展,处理多重应答数据的新方法也不断出现,除上述诸方法之外,还有分类数据的主成分分析方法(Categorical Principal Components Analysis, CATPCA)等其他多元统计分析方法,但由于其统计原理较为复杂,对此我们将另文专述。